How to set up a crawl
1. Enter a target URL
This is the starting point. Spidra loads this page first and follows links from it. Good starting points are index, category, or listing pages — not individual content pages. For example,https://example.com/blog works better than https://example.com/blog/my-specific-post.

2. Set crawl instructions
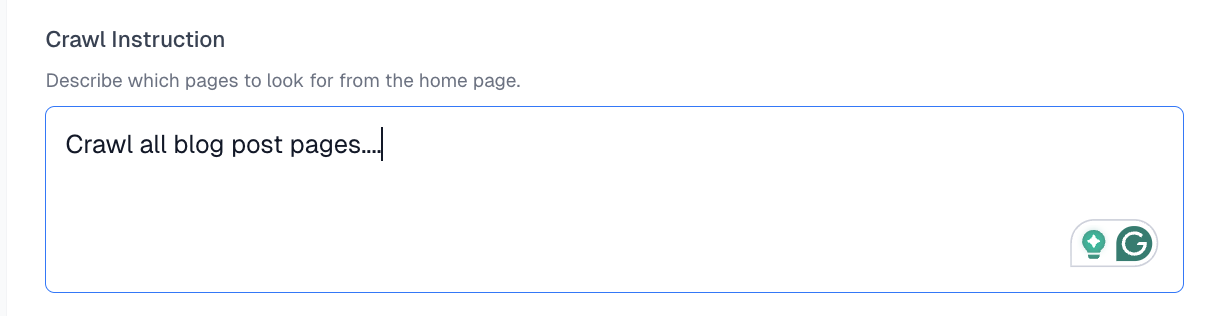
Tell Spidra which pages to follow, in plain language. This controls which links get visited and which get ignored. Examples:Crawl all blog post pagesVisit product pages onlyFollow links in the /docs/ section
3. Set transform instructions (optional)
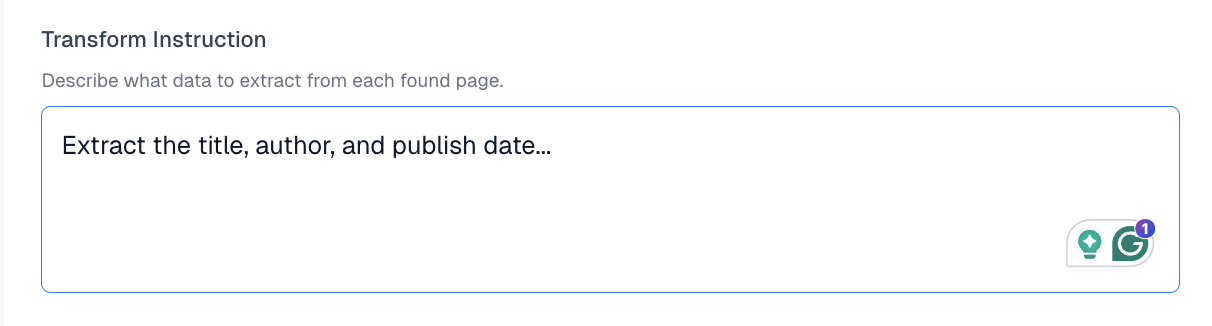
Describe what to extract from each page. Every page in the crawl is processed with the same instruction. Examples:Extract the title, author, and publish dateGet the product name, price, and descriptionPull the main article content
4. Define an output schema (optional)
Use a schema when you need every page to return the same fields in the same format. Spidra’s schema editor lets you define fields visually — pick a type, mark which are required, and add nested objects or arrays. When a schema is set, the AI returns JSON matching it exactly for every page. This is useful when you’re storing results in a database or processing them programmatically. You can set a schema alongside a transform instruction, or use it on its own.5. Set max pages
Cap how many pages the crawl visits. The default is 5. The maximum is 50.
Advanced options
Path filters
Use Include paths and Exclude paths to narrow the crawl to specific sections of a site.- Include paths — Only pages whose URL paths match one of your patterns are visited. For example,
/blog/*limits the crawl to pages under/blog/. - Exclude paths — Pages matching any pattern are skipped. For example,
/tag/*prevents tag pages from being crawled.
Max depth
Limits how many links deep the crawler goes from the base URL.0 means only the base URL itself. 1 means the base URL and pages directly linked from it. Leave it blank for unlimited depth.
Domain options
- Allow subdomains — Follows links to subdomains of the base domain (e.g.
docs.example.comwhen your base isexample.com). - Crawl entire domain — Follows any link on the same root domain, regardless of the starting path. Combine this with path filters to keep the scope manageable.
- Ignore query parameters — Treats URLs that differ only by query string as the same page. Useful on sites that append tracking parameters to every link.
Webhook
Provide a webhook URL to receive a POST request each time a page finishes processing. This lets you stream results into your own pipeline as they come in, rather than waiting for the whole job to complete.Features
- Smart page discovery — Spidra uses your crawl instruction to decide which links to follow. It ignores navigation menus, login pages, and other links that don’t match what you’re looking for.
- AI-powered extraction — When a transform instruction or schema is set, each page is processed with AI to extract exactly the data you described. No selectors or XPath needed.
- Raw markdown mode — When no transform instruction or schema is set, each page’s
datafield contains the plain markdown of that page. No AI is used, no token credits are charged. Useful for feeding content into your own AI pipeline. - Automatic CAPTCHA solving — Spidra handles CAPTCHAs automatically during the crawl.
- Stealth mode — Enable proxy routing to reduce blocks and rate limits on sites with bot detection.
- Download results — After a crawl completes, download all extracted data as a ZIP file containing: the extracted content, raw markdown, and original HTML snapshots for each page.
- Retry failed pages — If extraction fails on specific pages, retry them individually without re-crawling the whole site.
Extract from Crawl
After a crawl finishes, you can run a new extraction on the same pages without visiting the site again. Spidra reuses the HTML and markdown saved during the original crawl and runs your new prompt against it. This is useful when:- You want to pull different fields from pages you already crawled
- Your first extraction prompt wasn’t quite right
- You need the same pages in two different formats
POST to /crawl/{jobId}/extract with a new transformInstruction. You’ll get back a new jobId to poll.
Extract from Crawl API Reference
Full API reference for the extract endpoint
Tips
- Be specific with crawl instructions.
"All blog posts from 2024"works better than"crawl everything". Clear constraints lead to cleaner results and fewer wasted pages. - Start with 3–5 pages. Validate your crawl and transform instructions on a small set before scaling up.
- Use path filters on large sites.
includePathsandexcludePathsare the fastest way to keep a crawl focused without relying entirely on the crawl instruction. - Choose the right starting URL. Make sure your target URL links to the pages you want. Index and listing pages are usually the right choice.